Литературная ролевая игра с ИИ становится гораздо глубже и интереснее, когда у мира есть собственная история, правила и детали. Лорбук (Lorebook) — это инструмент, который позволяет добавить в игру базу знаний: описания мест, персонажей, событий, артефактов и любых других элементов мира.
Когда в диалоге встречаются ключевые слова или похожий по смыслу контекст, ИИ может автоматически подтягивать информацию из лорбука. Это помогает делать ответы богаче, а сюжет — более связным и последовательным.
В этой статье разберём:
- что такое лорбук и зачем он нужен;
- какие форматы поддерживает LiterAI;
- как устроен JSON-лорбук;
- как работает поиск записей;
- как настроить векторный поиск;
- как создать свой первый лорбук пошагово.
Что такое лорбук и зачем он нужен
Лорбук — это набор записей, которые ИИ использует как дополнительный контекст при генерации ответов. По сути, это энциклопедия вашего мира, доступная модели во время игры.
Например, если в сообщении появляется упоминание «Таверны “Драконья чешуя”» или персонажа «Мудрый старик», лорбук может автоматически добавить в контекст описание этого места или NPC. Благодаря этому история остаётся последовательной, а персонажи и локации не теряют свои особенности.
Что умеет лорбук
- Поиск по ключевым словам — запись активируется, если в сообщении встречается заданный триггер.
- Приоритеты — можно указать, какие записи важнее остальных.
- Рекурсивное сканирование — одна активированная запись может активировать другие.
- Векторный (смысловой) поиск — система находит записи даже без точного совпадения слов, если смысл близок.
Форматы лорбука в LiterAI
LiterAI поддерживает два формата загрузки лорбука: JSON и TXT.
JSON — рекомендуемый формат
Это основной и наиболее функциональный формат. Он позволяет использовать все настройки лорбука: приоритеты, дополнительные ключи, рекурсию, вероятности активации и другие параметры.
Файл должен иметь расширение .json.
TXT — упрощённый формат
Этот формат подходит для быстрого импорта простых записей. Поддерживаются два варианта:
1. Запись в квадратных скобках
[Название записи] Текст записи... 2. Строка с разделителем |
ключ1, ключ2 | Текст записи При импорте TXT-файла все записи получают значения по умолчанию: включены, приоритет 10 и так далее.
Структура JSON-лорбука
Полный объект лорбука выглядит так:
{ "name": "Название лорбука", "description": "Краткое описание", "scanDepth": 4, "tokenBudget": 8048, "recursiveScanning": false, "entries": [ ... ] } Основные поля
| Поле | Тип | Описание |
|---|---|---|
name |
string | Название лорбука, которое отображается в интерфейсе. |
description |
string | Краткое описание лорбука. Необязательное поле. |
scanDepth |
number | Количество последних сообщений, которые сканируются на наличие ключей. По умолчанию — 4. |
tokenBudget |
number | Максимальное количество токенов, которое может занять текст из лорбука в промпте. По умолчанию — 8048. |
recursiveScanning |
boolean | Включает рекурсивное сканирование: активированные записи могут запускать поиск других записей. |
entries |
array | Массив записей лорбука. |
Структура одной записи
{ "uid": "уникальный_идентификатор", "name": "Название записи", "keys": ["ключ1", "ключ2"], "secondaryKeys": ["доп_ключ1", "доп_ключ2"], "content": "Текст записи, который будет вставлен в контекст при активации", "enabled": true, "constant": false, "selective": false, "selectiveLogic": 0, "priority": 10, "probability": 100, "caseSensitive": false, "excludeRecursion": false } Поля записи
| Поле | Тип | По умолчанию | Описание |
|---|---|---|---|
uid |
string / number | — | Уникальный идентификатор записи. Обязательное поле. |
name |
string | — | Название записи, отображаемое в интерфейсе. В поиске не участвует. |
keys |
array of strings | [] | Основные ключевые слова. Если найдено совпадение, запись активируется. |
secondaryKeys |
array of strings | [] | Вторичные ключи. Используются только при selective: true. |
content |
string | — | Текст записи, который добавляется в контекст при активации. |
enabled |
boolean | true | Если false, запись игнорируется при поиске. |
constant |
boolean | false | Если true, запись всегда активна, даже без проверки ключей. |
selective |
boolean | false | Если true, для активации используются и основные, и вторичные ключи. |
selectiveLogic |
number | 0 | Логика работы selective: 0 — нужны совпадения и по keys, и по secondaryKeys; 1 — нужно совпадение по keys, но не по secondaryKeys. |
priority |
number | 10 | Чем выше значение, тем выше запись окажется в итоговом списке. |
probability |
number | 100 | Вероятность активации записи в процентах. |
caseSensitive |
boolean | false | Учитывать ли регистр символов при поиске. |
excludeRecursion |
boolean | false | Если true, запись не участвует в рекурсивном сканировании. |
Как работает поиск в лорбуке
1. Классический поиск по ключевым словам
- Система берёт несколько последних сообщений в зависимости от параметра
scanDepth. - Для каждой записи проверяется:
- если
constant = true, запись добавляется сразу; - иначе выполняется поиск совпадений по
keys; - если включён
selective, дополнительно проверяютсяsecondaryKeysпо логикеselectiveLogic.
- если
- Если запись проходит условия и срабатывает
probability, она попадает в активный список. - Записи сортируются по убыванию
priority. - Из активных записей собирается итоговый блок текста с учётом ограничения
tokenBudget.
2. Рекурсивное сканирование
Если recursiveScanning = true, после первого прохода система повторно анализирует уже активированные записи и ищет в них новые ключи. Это позволяет автоматически подтягивать связанные записи.
Например, запись о городе может активировать запись о районе, а та — запись о конкретной таверне.
3. Векторный поиск по смыслу
Если включён режим «Умный поиск (эмбеддинги)», лорбук может находить записи не только по точным словам, но и по смыслу.
Как это работает:
- Последние сообщения пользователя преобразуются в вектор через API эмбеддингов.
- Для записей лорбука используются заранее подготовленные векторы.
- Система сравнивает их по косинусному сходству.
- Если сходство выше заданного порога, запись активируется.
- Такие записи получают повышенный приоритет.
По умолчанию обычно используется порог около 0.75, но на практике удобно тестировать диапазон 0.3–0.4.
Как настроить векторный поиск
Чтобы использовать смысловой поиск, нужно выполнить несколько шагов.
Шаг 1. Включите умный поиск
Откройте настройки LiterAI, перейдите во вкладку «Лорбук» и активируйте переключатель «Умный поиск (Эмбеддинги)».
Шаг 2. Укажите URL API эмбеддингов
LiterAI совместим с OpenAI-подобными API, поддерживающими эндпоинт /v1/embeddings.
Примеры:
- OpenRouter:
https://openrouter.ai/api/v1/embeddings - Локальный сервер:
http://localhost:11434/v1/embeddings
Шаг 3. Укажите модель эмбеддингов
Например:
nvidia/llama-nemotron-embed-vl-1b-v2:freenomic-embed-text
Шаг 4. При необходимости добавьте API Key
Если сервис требует авторизацию, введите ключ API в соответствующее поле.
Шаг 5. Настройте порог сходства
Рекомендуемый диапазон — от 0.7 до 0.8. Но для каждой модели он индивидуален, проверять сработал лорбук или нет можно во вкладке логирования. Например, для модели llama-nemotron-embed-vl-1b-v2:free лучше ставить диапазон — от 0.3 до 0.5
Шаг 6. Векторизуйте лорбук
После настройки нажмите кнопку «Векторизовать текущий Лорбук». Система отправит записи в API эмбеддингов и сохранит их векторы в памяти.
Важно: без этого шага векторный поиск работать не будет.
Пошаговое создание лорбука
Шаг 1. Определите, что должно быть в базе знаний
Сначала составьте список сущностей, которые хотите добавить в мир:
- локации;
- NPC;
- фракции;
- артефакты;
- исторические события;
- магические правила или особенности мира.
Для каждой записи заранее продумайте ключевые слова, по которым она будет активироваться.
Пример:
- Запись: Таверна «Уставший путник»
- Ключи: «таверна», «уставший путник», «гостиница»
- Содержание: описание таверны, владельца и особого эля
Шаг 2. Создайте JSON-файл
Ниже пример минимального рабочего лорбука:
{ "name": "Мой мир", "description": "Лорбук для приключений в королевстве", "scanDepth": 5, "tokenBudget": 4000, "recursiveScanning": true, "entries": [ { "uid": 1, "name": "Таверна «Уставший путник»", "keys": ["таверна", "уставший путник", "гостиница"], "content": "Старая таверна на рыночной площади. Хозяин — толстый добродушный гном по имени Торвин. Здесь подают лучший эль в городе. За стойкой всегда можно услышать последние новости." }, { "uid": 2, "name": "Торвин", "keys": ["Торвин", "хозяин таверны", "гном"], "content": "Торвин — гном с рыжей бородой, всегда носит фартук с пятнами эля. Он знает всех в городе и готов помочь, если его угостить кружкой эля. Его отец основал эту таверну 80 лет назад.", "priority": 15, "selective": true, "secondaryKeys": ["таверна", "эль"] } ] } Шаг 3. Загрузите лорбук в LiterAI
- Откройте окно «Лорбук» через меню функций.
- Нажмите «Загрузить» и выберите JSON-файл.
- После загрузки проверьте список записей и их статус.
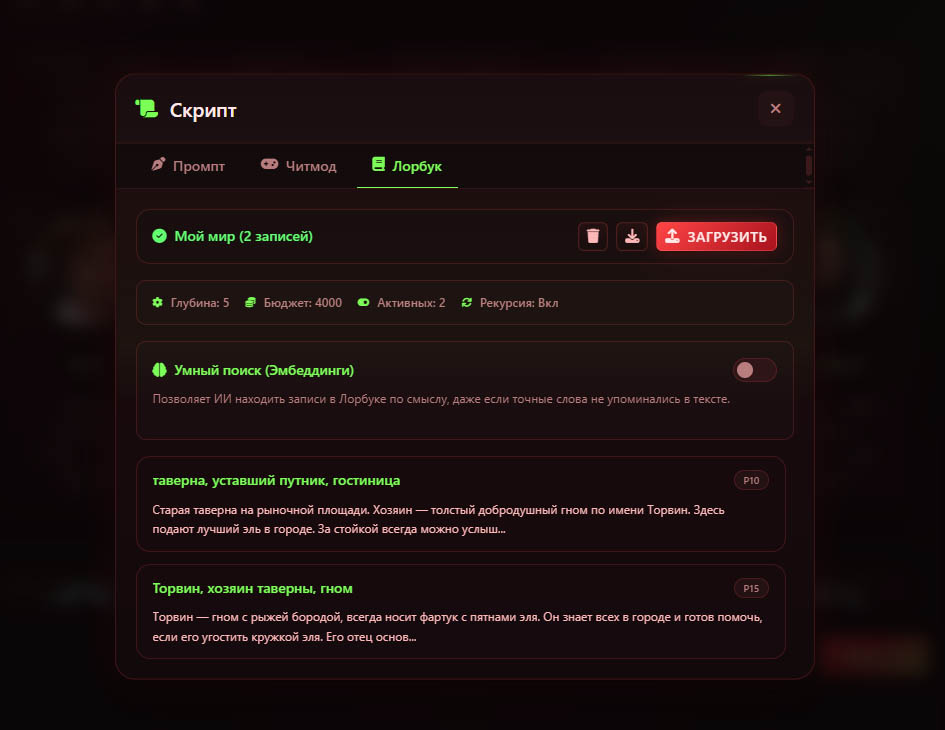
Шаг 4. При необходимости включите векторный поиск
- Перейдите в настройки → вкладка «Лорбук» → раздел «Умный поиск».
- Включите функцию и задайте URL, модель и порог.
- Нажмите «Векторизовать текущий Лорбук».
- Дождитесь завершения обработки.
Шаг 5. Проверьте результат
Начните новую игру или продолжите существующую. Используйте в сообщениях ключевые слова из лорбука и смотрите, какие записи активируются.
При необходимости откройте логи — там можно увидеть, какие записи были подтянуты в контекст.
Полезные советы
- Не перегружайте лорбук. Слишком большое количество записей может замедлить работу и быстро расходовать лимит токенов.
- Используйте приоритеты. Самые важные записи должны иметь более высокий
priority. - Продумывайте ключи. Добавляйте не только точные названия, но и распространённые варианты формулировок.
- Используйте рекурсию осознанно. Она особенно полезна для связанных сущностей: мир → город → район → здание.
- Тестируйте разные формулировки. Так вы поймёте, какие записи срабатывают стабильно, а какие нужно доработать.
- Подключайте векторный поиск, если нужен более «умный» контекст. Это особенно полезно в больших лорбуках с множеством похожих сущностей.
Заключение
Лорбук — это один из самых полезных инструментов для углубления мира в LiterAI. Он помогает хранить знания о персонажах, местах, предметах и событиях, а затем органично вплетать их в повествование.
Если использовать не только поиск по ключевым словам, но и векторный поиск, лорбук становится ещё гибче: система начинает лучше понимать контекст и может подбирать нужную информацию даже без точных совпадений.
Экспериментируйте со структурой записей, настраивайте приоритеты, тестируйте разные подходы и постепенно развивайте свою базу знаний. Чем лучше организован лорбук, тем живее и убедительнее будет ваш игровой мир.
Удачных приключений!







