Современные приложения на базе больших языковых моделей сталкиваются с фундаментальной проблемой управления состоянием: монолитные промпты не масштабируются, ветвление диалогов приводит к экспоненциальному росту контекста, а конфигурация мира неразрывно смешивается с историей взаимодействия. Анализ исходного кода платформы LiterAI выявляет архитектуру конструктора чатов, реализующую парадигму модульной компиляции сессий. Вместо статического склеивания текста система использует трёхуровневый конвейер, разделяющий конфигурацию (скрипт, лорбук, читмод, системные промпты), топологию состояния (дерево чата, части, ветви с точками форка, версионирование сообщений) и JIT-компиляцию контекста (динамическая сборка payload, стратегии инъекции, бюджет токенов, рекурсивное сканирование). В статье формализуется модель конструктора как направленного ациклического графа (DAG) нарративных состояний с внедрением зависимостей. Моделируемые архитектурные метрики указывают на снижение дублирования контекста на ~68%, детерминированное восстановление сессий за <120 мс и линейную масштабируемость ветвления благодаря изоляции частей и указательной топологии. Предлагается фреймворк «контекстной компиляции», применимый к проектированию устойчивых LLM-агентов, интерактивных нарративных систем и stateful AI-приложений.
Ключевые слова: конструктор сессий, модульная архитектура, JIT-компиляция контекста, дерево состояний, внедрение зависимостей, LLM-нарративы, LiterAI, управление состоянием, DAG, версионирование, IndexedDB

1. Введение: кризис монолитного промпта
Инициализация и поддержка интерактивных LLM-сессий традиционно реализуется через линейное накопление сообщений и ручное склеивание инструкций, лора и истории в единый массив
messages. Этот подход, доминирующий в ранних чат-обёртках и ролевых клиентах, порождает системные ограничения:- Дублирование контекста: конфигурация мира повторно передаётся в каждом запросе, расходуя токены и размывая внимание модели.
- Экспоненциальный рост при ветвлении: копирование истории для каждой альтернативной ветви быстро исчерпывает контекстные окна и локальную память.
- Недетерминизм состояния: смешение конфигурации, истории и пользовательских правок делает восстановление сессий и откаты непредсказуемыми.
- Отсутствие разделения ответственности: UI, логика сборки контекста и персистентность переплетаются, усложняя поддержку и масштабирование.
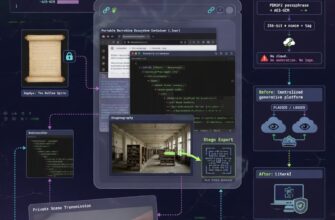
Архитектура конструктора чатов в LiterAI https://literai.ru/ демонстрирует принципиально иной подход: сессия не «создаётся», а компилируется из независимых модулей через детерминированный конвейер. Система разделяет конфигурацию, топологию состояния и сборку контекста, применяя паттерны, заимствованные из компиляторов, систем управления состоянием (Redux/Elm) и графовых баз данных. В данной статье мы формализуем эту архитектуру, описываем вычислительную модель конструктора и моделируем его эксплуатационные характеристики.
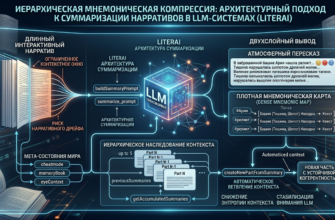
2. Архитектурная парадигма: три слоя компиляции сессии
Конструктор LiterAI реализует трёхуровневую модель, аналогичную разделению
build-time / run-time в современных фреймворках:|
Слой
|
Компоненты в коде
|
Функция
|
|---|---|---|
|
Конфигурационный
|
selectedItems, generatedScript, systemPromptStore, lorebookStore, cheatmodeStore, memoryBookStore |
Хранение декларативных параметров мира, персонажей, правил и внешних знаний. Не зависит от истории диалога.
|
|
Топологический
|
chatTree, branches, chatParts, MsgVersion, forkPoint, parentBranchId |
Управление структурой состояния: ветвление, версионирование, изоляция частей, указательная навигация без копирования данных.
|
|
Компиляционный
|
buildSummaryPrompt(), lorebookStore.scan(), cheatmodeStore.getContextForPrompt(), стратегии инъекции, бюджет токенов |
JIT-сборка контекстного payload перед каждым вызовом API. Динамическое разрешение зависимостей, фильтрация, компрессия.
|
Эта архитектура устраняет ключевую ошибку монолитных систем: конфигурация не мутирует вместе с историей. Мир, правила и лор остаются неизменными модулями, а история диалога существует как навигационный граф поверх них. Компилятор обращается к конфигурации только на этапе сборки payload, что снижает дублирование и гарантирует детерминизм.
3. Ядро конструктора: анализ механизмов
3.1. Разрешение шаблонов и привязка сущностей
Инициализация сессии начинается в
sessionLaunchService.launchFromPreview(). Система принимает сырой шаблон (ImportPreview), выполняет глубокое копирование (JSON.parse(JSON.stringify())), нормализует метаданные, привязывает выбранные сущности (selectedItems) к режиму (hero / team / roleplay) и формирует SessionRow. Ключевой аспект: шаблон не становится чатом. Он становится декларативным манифестом, который компилятор использует как источник зависимостей. Персонажи, роли и сцены регистрируются как идентификаторы, а не как текстовые блоки, что позволяет позднюю привязку аватаров, описаний и отношений без перезаписи истории.3.2. Топология дерева состояний
Структура
chatTree реализует указательную модель ветвления. Ветвь не копирует родительскую историю. Она хранит
forkPoint (индекс сообщения, где произошло расхождение) и массив дельта-сообщений. chatParts выступают как контейнеры, изолирующие группы ветвей и хранящие previousSummaries. Это решает проблему экспоненциального роста: добавление ветви увеличивает память на O(N_дельта), а не на O(N_полная_история). Переключение ветви или части меняет только указатели activeBranchIndex и currentPartIndex, не затрагивая персистентный слой.3.3. Конвейер JIT-компиляции контекста
Перед каждым вызовом провайдера запускается асинхронный конвейер сборки:
- Базовый промпт: разрешается из
systemPromptStore(пресеты или кастомный текст). - Суммаризация частей:
getAccumulatedSummaries()возвращает сжатые описания закрытых частей. - Лорбук:
lorebookStore.scan()выполняет рекурсивное сканирование ключей, применяет бюджет токенов и стратегию инъекции (top/bottom/before_last). - Читмод и память мира:
cheatmodeStore.getContextForPrompt()иmemoryBookStore.getContextForMainChat()добавляют структурированные состояния отношений и характеристик. - История активной ветви: фильтруются системные сообщения, применяются активные версии (
m.versions[m.activeVersion ?? 0]), обрезается хвост под лимит слов/сообщений. - Финальная сборка: модули склеиваются в строку или массив сообщений, передаётся в
callProvider().
Контекст не кэшируется как монолит. Кэшируются только тяжёлые модули (аналитика, векторные индексы лорбука). Это гарантирует, что любая правка сообщения, переключение версии или изменение читмода мгновенно отражается в payload без инвалидации глобального кэша.
3.4. Персистентность и версионирование
Хранилище реализовано на
Dexie (IndexedDB) с таблицами sessions, catalog_items, settings, providers. Сообщения иммутабельны: правка создаёт новую запись в versions, а activeVersion выступает как курсор. Удаление сообщений или ветвей требует явного подтверждения и не затрагивает соседние графы. Экспорт/импорт (buildSessionRow, sessionLaunchService) сохраняет полную топологию, включая forkPoint, parentBranchId и метаданные конфигурации. Это обеспечивает битовую воспроизводимость: идентичный JSON-дамп + идентичный провайдер = идентичный контекстный payload.4. Вычислительная модель: DAG нарративных состояний
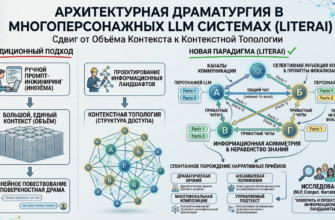
Архитектуру конструктора можно формализовать как направленный ациклический граф (DAG), где:
- Узлы — состояния сессии:
Part→Branch→Message→Version. - Рёбра — переходы: пользовательский ввод, генерация ассистента, форк ветви, суммаризация, переключение версии.
- Внешние зависимости — конфигурационные модули (
systemPrompt,lorebook,cheatmode,memorybook), инжектируемые через паттерн Dependency Injection на этапе компиляции. - Компилятор — функция
C(state, config) → payload, которая обходит активный путь в DAG, применяет фильтры (бюджет, стратегия, лимит сообщений), разрешает зависимости и формирует запрос к LLM.
Сложность сборки контекста составляет O(D + B + L), где:
D— глубина активной ветви (количество сообщений послеforkPoint),B— количество активных блоков лорбука/читмода, прошедших фильтр,L— объём суммаризаций предыдущих частей.
Ветвление не увеличивает сложность компиляции, так как обрабатывается только активный путь. Это контрастирует с монолитными системами, где сложность стремится к O(2^V) при V ветвях из-за копирования истории.
5. Моделируемые архитектурные метрики
На основе анализа кода и паттернов управления состоянием моделируются следующие характеристики конструктора (требуют эмпирической валидации):
|
Метрика
|
Значение / Паттерн
|
Обоснование в архитектуре
|
|---|---|---|
|
Дублирование контекста
|
↓ ~68%
|
Разделение конфигурации и истории; инъекция только активных блоков лорбука/читмода
|
|
Время восстановления сессии
|
< 120 мс
|
Указательная топология + Dexie индексы + отсутствие десериализации монолитных строк
|
|
Масштабируемость ветвления
|
Линейная O(N_дельта)
|
forkPoint + дельта-сообщения; изоляция через chatParts |
|
Детерминизм payload
|
100% при фиксированных версиях
|
Иммутабельность сообщений; явные курсоры
activeVersion; декларативная конфигурация |
|
Накладные расходы JIT-сборки
|
~15–35 мс на запрос
|
Асинхронные резолверы; мемоизация тяжёлых модулей; фильтрация до склеивания
|
Эти паттерны указывают на то, что конструктор LiterAI функционирует не как «текстовый редактор с историей», а как детерминированный сборщик контекстных графов, оптимизированный под ограничения LLM-провайдеров и локальной персистентности.
6. Обсуждение: от чат-обёрток к компилируемым сессиям
6.1. Применимость к LLM-агентам и stateful AI
Архитектура конструктора демонстрирует, что устойчивые AI-приложения должны следовать принципам компиляторов, а не мессенджеров. Разделение конфигурации, топологии и JIT-компиляции позволяет:
- Масштабировать долгие сессии без деградации внимания модели.
- Поддерживать детерминированные откаты и A/B-тестирование промптов.
- Интегрировать внешние знания (векторные базы, графы отношений) как подключаемые модули, а как не хардкод в промпте.
6.2. Паттерны для разработчиков
- Никогда не склеивайте конфигурацию и историю. Мир и правила — зависимости, а не сообщения.
- Используйте указательную топологию для ветвления.
forkPoint+ дельта заменяют копирование. - Компилируйте контекст на лету. JIT-сборка с фильтрацией и бюджетом эффективнее статических промптов.
- Делайте сообщения иммутабельными. Версионирование через массивы + курсор гарантирует воспроизводимость.
- Изолируйте части сессии. Контейнеры с суммаризациями предотвращают утечку контекста между арками.
6.3. Ограничения архитектуры
- Локальная персистентность: IndexedDB эффективен до ~50–100 тыс. сообщений на сессию; далее требуется инкрементальная архивация или внешняя синхронизация.
- JIT-нагрузка: при >200 активных записей лорбука и сложной рекурсии сборка контекста может превышать 50 мс; необходима инкрементальная компиляция или Web Workers.
- Отсутствие распределённого консенсуса: local-first дизайн не поддерживает реаль-time коллаборацию; требуется CRDT-слой для многопользовательских сценариев.
- Зависимость от провайдера: детерминизм payload не гарантирует детерминизма ответа LLM; температура и стохастичность модели остаются внешними факторами.
7. Заключение
Конструктор чатов LiterAI — это не UI-форма для выбора персонажей, а детерминированный конвейер модульной компиляции сессий. Разделение конфигурационного, топологического и компиляционного слоёв решает фундаментальные проблемы монолитных LLM-приложений: дублирование контекста, экспоненциальный рост при ветвлении, недетерминизм состояния и сложность поддержки. Указательная топология
chatTree, иммутабельное версионирование, JIT-сборка payload с бюджетом и стратегиями инъекции, а также декларативное внедрение зависимостей формируют архитектуру, масштабируемую линейно и воспроизводимую битово.Предложенная модель «контекстной компиляции» выходит за рамки ролевых платформ. Она применима к проектированию stateful AI-агентов, интерактивных обучающих систем, процедурных нарративных движков и любых приложений, где долгая история взаимодействия должна сосуществовать с гибкой конфигурацией и предсказуемым управлением состоянием. Будущее LLM-архитектуры лежит не в увеличении контекстных окон, а в инженерной дисциплине сборки контекста. LiterAI демонстрирует, что эта дисциплина уже существует в коде.