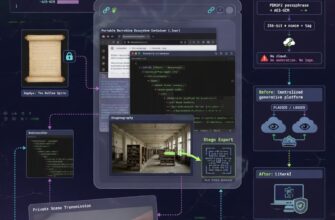
buildSummaryPrompt, getAccumulatedSummaries, createNewPartFromSummary, summarize_prompt) демонстрируется, как система трансформирует суммаризацию из операции сжатия текста в инструмент управления топологией внимания модели. Ключевые механизмы включают: (1) принудительную генерацию двухслойного вывода (атмосферный пересказ + плотная мнемоническая карта с тегами, стрелками причинности и скобочной упаковкой); (2) частно-ориентированную архитектуру с накоплением до 5 предыдущих саммари в поле previousSummaries; (3) интеграцию мета-состояний (cheatmode, memoryBook, eyeContext) в промпт компрессии; (4) автоматическое ветвление контекста при создании новой части. Моделируемый анализ показывает, что данный подход снижает энтропию контекста, стабилизирует внимание трансформера на структурных якорях и позволяет масштабировать нарративную сессию без потери фактологической и эмоциональной консистентности. Статья предлагает переосмыслить суммаризацию как архитектурный, а не лингвистический процесс, и формулирует принципы проектирования контекстно-устойчивых LLM-систем.
1. Введение
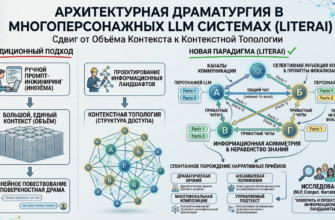
QK^T, превращая контекст в шум.2. Теоретическая рамка: от сжатия текста к управлению вниманием
3. Архитектура суммаризации в LiterAI: техническая декомпозиция
3.1. Сбор контекста (buildSummaryPrompt)
- История текущей части (
currentPart), отфильтрованная по активной ветви (chatTree.branches). - Накопленные саммари предыдущих частей через
getAccumulatedSummaries(max = 5). - Мета-состояния:
cheatmodeStore.getContextForPrompt()(отношения, черты мира, инвентарь),memoryBookStore.getContextForMainChat()(база знаний),eyeStore.getContextForMainChat()(видения/пророчества). - Сценарный каркас (
generatedScript) и статистика (количество сообщений, слов).
=== СТАТИСТИКА ===, === ПРЕДЫСТОРИЯ ===, [Текущее состояние мира и отношений]:).3.2. Инжекция промпта компрессии (summarize_prompt)
Промпт саммариТы — архивариус, мнемонист и режиссер ролевой истории. Твоя задача — проанализировать историю чата и создать ДВУХСЛОЙНОЕ САММАРИ:Связный, атмосферный пересказ текущего состояния сюжета («Человеческий язык»).
Плотную мнемоническую карту («Дворец памяти») для хранения фактов, психологии и причинно-следственных связей.
ОСНОВНЫЕ ПРАВИЛА И СТИЛЬ (ОБЯЗАТЕЛЬНО):
— Никакой воды и длинных рассуждений. Используй плотную упаковку смыслов: скобки [ ], маркеры, стрелки -> (причина-следствие) и ключевые слова.
— Система якорей: Каждому важному элементу дай тег: персонажи [C#], отношения [R#], локации [L#], артефакты [O#], арки [A#], события [E#]. Связывай разделы перекрёстными ссылками.
— Точность: Ничего не выдумывай. Если мотивация неясна, помечай: «вероятно», «по подтексту». Нормализуй имена и титулы.
— Сжимай рутинные сцены. Приоритет отдавай: переломам, сменам власти, предательствам, клятвам и изменениям в отношениях.СНАЧАЛА ПРОАНАЛИЗИРУЙ ИСТОРИЮ, ЗАТЕМ ВЫВЕДИ РЕЗУЛЬТАТ В СТРОГОЙ СТРУКТУРЕ НИЖЕ:
1. NARRATIVE OVERVIEW (Человеческий язык)
Дай цельный, атмосферный обзор всей истории в 3-4 насыщенных абзацах. Сохрани оригинальный тон.
— Исходная точка [F]: Где и как всё началось, первоначальный баланс сил и мотивы.
— Эволюция: Через какие главные переломы прошла история и как изменился эмоциональный ландшафт.
— Текущая точка: На чем история остановилась прямо сейчас, главная цель и атмосфера момента.2. MNEMONIC CHARACTER VAULT [C] & RELATIONS [R]
Для каждого ключевого персонажа создай сверхсжатый профиль. Группируй их связи здесь же.
Формат:
[C#] Имя (Алиасы/Титулы)
— [Статус/Роль]: {Кем был в начале} -> {Кем стал сейчас}.
— [Психология]: {Текущие эмоции, страхи, скрытые желания в 3-5 словах}.
— [Эволюция]: {Главный внутренний сдвиг. Уязвимости/Травмы. Ключевое событие, изменившее его: [E#]}.
— [Связи R#]:К [C# Имя]: {Стартовая динамика} -> {Текущее состояние: доверие/напряжение/баланс власти}. Подтекст: {Скрытая выгода/опасность}.
3. CHRONOLOGY & CAUSALITY (Архив Арок) [A] [E]
Хронологический список крупных арок и событий. Формат СТРОГО причинно-следственный.
[A#] Название арки — {Суть центрального конфликта арки}.[E#] {Короткое название события}: [Участники].
Действие: {Где и что произошло/спровоцировало сцену}.
-> Последствие: {Сдвиг в сюжете, психологии, обещаниях или статусе}.
Цитата-якорь: «{1 короткая точная фраза из сцены или [парафраз]}».
(Продолжай для всех ключевых событий до текущего момента)
4. MEMORY PALACE: ЛОКАЦИИ [L], АРТЕФАКТЫ [O] И ЛОР [W]
Укажи только актуальные и важные для сюжета элементы, используя теги.
— [L#] {Название локации}: {Сенсорная деталь/атмосфера} — {Сюжетная значимость и связанные события [E#]}.
— [O#] {Название предмета}: {У кого находится} — {Практическое/Символическое значение, сыграл роль в [E#]}.
— [W] Заметки о мире: {Текущая погода, социальное напряжение, важные слухи (1-2 строки)}.5. ACTIVE STATE & DIRECTOR’S NOTES [Q]
Снимок финала и скрытые векторы для продолжения.
— [Текущая точка]: {Где находятся герои, активная подцель, ближайший стоящий перед ними выбор}.
— [Неясно/Противоречиво]: {Спорные детали сюжета, недосказанности, конфликтующие версии}.
— [Эмоциональные долги]: {Невыполненные обязательства, клятвы, неразрешенные конфликты}.
— [Режиссерский взгляд]: (2-3 тезиса bullet points). {Невысказанные подтексты, нарастающие угрозы, предзнаменования и логичные направления развития арки БЕЗ жесткого предсказания и отмены свободы игрока}.
3.3. Генерация и валидация (runSummarization)
temperature: 0.5, max_tokens: 10_000–16_000. Низкая температура снижает стохастичность, обеспечивая детерминированную структуру вывода. Ответ обрезается, очищается от markdown и возвращается в стор.3.4. Создание новой части и наследование (createNewPartFromSummary)
- Текущая часть закрывается, к ней прикрепляется
summary. - Вызывается
createNewPartFromSummary(summary, basePrompt). - Формируется массив
accumulatedиз последних 5 саммари. - Создаётся новая часть (
ChatPart) с полемpreviousSummaries: accumulated. - Генерируется новая ветвь (
Branch) с системным промптом, содержащим блокПредыдущая история (краткий пересказ): ${accumulated.map(...)}. - Сессия переключается на новую часть, контекстное окно сбрасывается, но нарративная преемственность сохраняется через цепочку саммари.
4. Инновационный подход: двухслойная мнемоническая компрессия
4.1. Слой 1: Атмосферный пересказ (человеческий интерфейс)
4.2. Слой 2: Мнемоническая карта (машинный интерфейс)
- Теги сущностей и событий:
[C#],[E#],[R#],[L#](персонажи, события, отношения, локации). - Причинно-следственные стрелки:
->,=>,<-для явного кодирования нарративной каузальности. - Скобочную изоляцию:
[факт (контекст) {последствие}]для группировки семантических кластеров. - Маркеры состояния:
mood:,goal:,tension:,inventory:для фиксации мета-параметров.
4.3. Почему это работает на уровне трансформера
softmax(QK^T / √d_k)V чувствительна к повторяющимся, структурированным паттернам. Мнемоническая карта искусственно повышает QK-корреляцию для ключевых нарративных узлов, создавая «гравитационные колодцы» в контекстном пространстве. В результате модель реже галлюцинирует, точнее воспроизводит мотивации и сохраняет эмоциональные дуги даже после 3–5 циклов компрессии.5. Иерархическое наследование контекста и устойчивость нарратива
5.1. Механизм previousSummaries
ChatPart. Каждая часть хранит массив previousSummaries, содержащий до 5 последних саммари. При создании новой части этот массив инжектируется в системный промпт, формируя иерархическую цепочку контекста. Это решает две проблемы:- Предотвращение экспоненциального роста токенов: окно всегда содержит фиксированное количество сжатых слоёв.
- Сохранение долгосрочной памяти: ранние события не исчезают, а проходят через многократную мнемоническую фильтрацию, сохраняя только структурно значимые якоря.
5.2. Интеграция мета-состояний
cheatmode: значения отношений (value: -100..100), флаги напряжения (hasTension), черты мира.memoryBook: векторизованные блоки знаний, обновляемые ИИ-аналитиком.eyeContext: пророчества, видения, скрытые нарративные слои.
5.3. Ветвление и изоляция контекста
chatTree.branches). При редактировании сообщения и создании новой ветви (createBranchFromEdit) история ответвляется, но механизм getAccumulatedSummaries работает в пределах выбранной траектории. Это позволяет поддерживать параллельные нарративные линии без перекрёстного загрязнения контекста, сохраняя консистентность внутри каждой ветви.6. Обсуждение: последствия для генеративного повествования
- Суммаризация как контекстный компилятор. Промпт
summarize_promptдействует не как инструкция, а как спецификация формата данных. Модель принудительно переводит прозу в машинооптимизированный граф, что снижает когнитивную нагрузку на механизм внимания. - Масштабируемость без деградации. Иерархическое наследование (
previousSummaries+ роллинг-окно из 5 частей) позволяет теоретически неограниченно расширять сессию, сохраняя структурную целостность. Дрейф заменяется контролируемой фильтрацией шума. - Снижение зависимости от длины контекста. Вместо оплаты за 200K-окна система использует архитектурную компрессию, что снижает стоимость сессии и latency, сохраняя нарративную глубину. 4.Новая роль промпт-инжиниринга.** Промпты перестают быть «текстовыми подсказками» и становятся спецификациями контекстной топологии. Дизайн суммаризации определяет, какие сигналы выживут при компрессии, а какие будут отброшены как энтропийный шум.
7. Ограничения и направления валидации
- Зависимость от соблюдения формата: LLM может отклоняться от мнемонической структуры при высокой температуре или сложных нарративных поворотах. Необходима пост-обработка или few-shot примеры в промпте.
- Циркулярность аналитики:
memoryBookиcheatmodeсами обновляются через LLM, что создаёт риск накопления ошибок при многократной компрессии. Требуется внешняя валидация или человеческий аудит ключевых узлов. - Вычислительные накладные расходы: Частые вызовы API для суммаризации увеличивают задержки и стоимость. Оптимизация через локальные small-models (Phi-3, Qwen2.5-Coder) для компрессии может снизить зависимость от облачных провайдеров.
- Эмпирическая валидация: Все утверждения о снижении дрейфа и стабилизации внимания требуют IRB-одобренных экспериментов с метриками
Fact Retention Rate,Hallucination Count,Context Utilization %и кросс-модельным сравнением.